| Version 10 (modified by , 13 years ago) (diff) |
|---|
Condor-B: BOINC/Condor integration
This document describes the design of Condor-B, extensions to BOINC and Condor so that a BOINC-based volunteer computing project can provide computing resources to a Condor pool.
A central design goal is transparency: from the job submitter's viewpoint, things should look exactly like Condor: i.e. they prepare Condor submit files and use condor_submit.
Condor-B must address some basic differences between Condor and BOINC:
- Data model:
- In BOINC, files have both logical and physical names. Physical names are unique within a project, and the file associated with a given physical name is immutable. Files may be used by many jobs. In Condor, a file is associated with a job, and has a single name.
- BOINC is designed for apps for which the number and names of output files is fixed at the time of job submission. Condor doesn't have this restriction.
- Application concept: In Condor, a job is associated with a single executable, and can run only on hosts of the appropriate platform (and possibly other attributes, as specified by the job's ClassAd). In BOINC, there may be many app versions for a single application: e.g. versions for different platforms, GPU types, etc. A job is associated with an application, not an app version.
BOINC environment choices
BOINC offers three "environments" in which applications can be deployed:
- Native: This requires making source-code modifications and recompiling for different platforms, linking with the BOINC API library.
- Virtual machine-based: This would eliminate multi-platform issues but would require volunteer hosts to have VirtualBox installed.
- BOINC wrapper: Requires apps to be built for different platforms, but no source code mods.
Using the BOINC wrapper is the path of least resistance at this point.
The Condor pool admins will select a set of applications to run under BOINC. For each app, they must
- Create a BOINC "application"
- Create input and output templates
- Compile the app for one or more platforms
- Create BOINC "app versions", with associated job.xml files for the wrapper
Data model
Goal: minimize data transfer and storage on the BOINC server. To do this, we'll add the following mechanism to BOINC:
- DB tables for files, and for batch/file associations (with lease ends). File names will be based on MD5s.
- Web RPCs for querying and uploading files.
- Daemon for deleting files and DB records of files with no associations, or past all lease ends.
For output files, we'll take the approach that each job has (from BOINC's viewpoint) a single output file, which is a zipped archive of its actual output files. This will get copied to the submitter host, unzipped, and its components moved to the appropriate directory.
Job submission mechanism
We'll use Condor's existing mechanism for sending jobs to non-Condor back ends. This will involve 2 components:
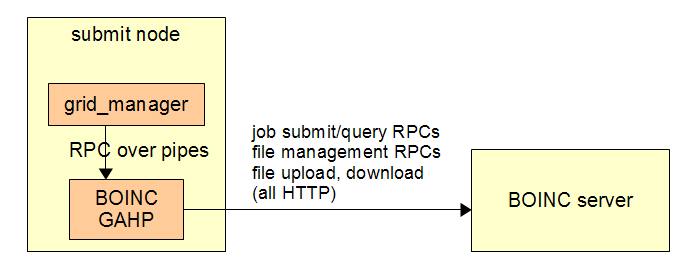
- A "BOINC GAHP" program: runs as a daemon process on the submit node.
This does the following:
- Handle RPCs (over pipes) from the Condor job router to submit and monitor jobs.
- Periodically poll the BOINC server for completed jobs; when a job is newly completed, download its output from the BOINC server, and store it into the appropriate directories on the submit node.
- A new class in Condor's job_router for managing communication with the BOINC GAHP.

GAHP protocol
The API exported by the BOINC GAHP has the following functions:
submit_jobs()
inputs:
batch_name (unique within project)
app_name
jobs
job name
cmdline
for each input file
path on submit node
name by which app will open file
bool return_all_output_files (or regular expression)
if the above not set
for each output file
open name (what the app will create)
final name (e.g. may have process appended)
directory where output file(s) go
output:
error code
The BOINC GAHP handles this as follows:
- Make list of all input files
- Eliminate duplicates in file list
- Compute MD5s of files
- BOINC physical name of each file is condorb_(md5)
- Do query_files() RPC to see which files are already on BOINC server
- Do upload_files() RPC to copy needed files to BOINC server
- Do submit_jobs() RPC to BOINC server; create batch, jobs
query_batch
in: batch name
out: list of jobs
job name
status (done/error/in prog/not in prog)
query_job
in: job name
out: status
list of URLs of output files
abort_jobs in: list of job names
set_lease
in: batch name
new lease end time
BOINC Web RPCs
query_files() in: list of physical file names out: list of those not present on server
upload_files()
in: batch name
filename
file contents
out: error code
uploads files and creates DB records (see below)
submit_jobs() in: same as for GAHP, except include both logical and physical name out: error code
Atomicity
(We need to decide about this).
Authentication
All the above APIs will take a "credentials" argument, which may be either a BOINC authenticator or x.509 certificate; we'll need to decide this. Two general approaches:
- Each job submitter has a separate account on the BOINC project (created ahead of time in a way TBD). This is preferred because it allows BOINC to enforce quotas.
- All jobs belong to a single BOINC account.
Changes to BOINC
- The job creation primitives (create_work()) will let you directly specify the logical names of input files, rather than specifying them in a template.
- Add lease_end field to batch
BOINC GAHP implementation notes
The BOINC GAHP could be implemented in Python or C++. My inclination is to use Python; we can assume it's available on the submit node.
Attachments (1)
- condor.png (11.3 KB) - added by 13 years ago.
{kind=link}
Download all attachments as: .zip